Abstrakte Datentypen (2)
Als Beispiel für einen abstrakten Datentyp
betrachten wir lineare Listen
beliebiger Länge von Elementen
eines vorerst noch nicht festgelegten Typs T;
wir haben also einen parametrisierten oder generischen Typ,
manchmal auch Schema oder Schablone (template) genannt,
den wir später durch Festlegung von T noch spezialisieren können.
Die im folgenden verwendete Notation ist typisch, aber nicht genormt.
ADT Lists(T) IS
SORTS:
 list, T, boolean
list, T, boolean
OPERATIONS:
newlist:  list
list
cons: T 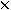 list list
list list
head: list 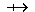 T
T
tail: list list
isempty: list boolean
RULES:
isempty(newlist) = true
isempty(cons(x, l)) = false
head(cons(x, l)) = x
tail(cons(x, l)) = l
END Lists.
Die Operationen newlist und cons sind Konstruktoren,
die anderen Operationen sind Projektoren.
Grundterme werden mit newlist und cons aufgebaut,
oder sind Grundterme der Sorten boolean oder T.
Beispielsweise läßt sich die Sequenz
<1, 2, 3, 4>
als Term schreiben:
cons(1, cons(2, cons(3, cons(4, newlist ))));
und daß hier so viele Klammern stehen, wie öfters in LISP,
ist kein Zufall.
Die Operationen head und tail sind
partielle Funktionen;
manche Terme wie tail(newlist) lassen sich daher nicht auf
Grundterme zurückführen.
Sie bezeichnen demnach keine Objekte;
in einer Implementierung ergeben sie keinen Sinn,
und sie sollten möglichst als Fehler erkannt werden.
Abstrakte Datentypen werden durch funktionale Sprachen und auch
manche objektorientierte Sprachen recht gut unterstützt;
in imperativen Sprachen wie etwa Modula 2 ergeben sich
oft rein technisch bedingte Einschränkungen,
bei denen man sich geeignet behelfen muß.
So sind meist nicht alle Typen als Funktionsresultate zugelassen;
dann arbeitet man statt dessen mit Ergebnisparametern,
muß aber daher Resultate zwischenspeichern.
zurück |
Inhalt | Index |
vor |
Vorlesung
Klaus Lagally, 22. Februar 2000, 19:35