Suchbäume (2)
Das Aufsuchen eines Datenelements in einem
Suchbaum unter Angabe seines
Suchschlüssels
geht ganz ähnlich wie das Eintragen:
man steigt in den Suchbaum hinab, bis man das Element an der Wurzel
eines Teilbaumes gefunden hat, oder bis man weiß,
daß es nicht vorhanden sein kann.
Weil man oft die gefundenen Daten modifizieren möchte,
liefern wir hier nicht die Daten selbst,
sondern nur einen Verweis darauf zurück,
der im Mißerfolgsfalle leer ist.
PROCEDURE lookup(k: keytype; b: stree): stree;
BEGIN IF b = NIL THEN RETURN NIL
ELSIF k < b^.key THEN RETURN lookup(k, b^.left);
ELSIF k > b^.key THEN RETURN lookup(k, b^.right);
ELSE (* k = b^.key *) RETURN b;
END;
END lookup;
Diese Routine ist nicht nur rekursiv,
sondern sogar rechtsrekursiv.
Darunter verstehen wir das folgende:
-
im rekursiven Fall ist nur ein einziges Teilproblem zu lösen,
-
dessen Lösung ist unmittelbar die Lösung
des Gesamtproblems.
Rechtsrekursive Routinen können wir leicht
iterativ und damit schneller machen,
sofern sie nur Wertparameter haben oder allenfalls Ergebnisparameter,
die identisch durchgereicht werden.
Wir stellen das hier zurück, weil wir später die
Suchverfahren
unter einem allgemeineren Aspekt besprechen wollen,
und dabei wird die Lösung mit abfallen.
So elegant unser Verfahren auch ist, gibt es doch ein paar Probleme.
Wenn man die Daten zufällig in aufsteigender Folge der Schlüssel
einträgt, so entartet der Baum zu einer linearen Kette,
und damit wird das Eintragen und Suchen mit 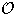 (n) unangenehm langsam;
es gibt noch andere Eingabefolgen mit dieser Eigenschaft.
Beim Eintragen in zufälliger Reihenfolge geschieht
dies zwar nicht; dann haben wir Aufwand (log n).
Aber wenn man die schlimmsten Fälle unbedingt vermeiden will,
so muß man zusätzliche Information im Baum mitführen,
etwa die Höhe oder die Knotenzahl der Teilbäume,
und notfalls den Baum gelegentlich reorganisieren.
Die Einzelheiten davon und geeignete Varianten (2-3-Bäume,
AVL-Bäume) gehören in eine Vorlesung über
Datenstrukturen.
(n) unangenehm langsam;
es gibt noch andere Eingabefolgen mit dieser Eigenschaft.
Beim Eintragen in zufälliger Reihenfolge geschieht
dies zwar nicht; dann haben wir Aufwand (log n).
Aber wenn man die schlimmsten Fälle unbedingt vermeiden will,
so muß man zusätzliche Information im Baum mitführen,
etwa die Höhe oder die Knotenzahl der Teilbäume,
und notfalls den Baum gelegentlich reorganisieren.
Die Einzelheiten davon und geeignete Varianten (2-3-Bäume,
AVL-Bäume) gehören in eine Vorlesung über
Datenstrukturen.
zurück |
Inhalt | Index |
vor |
Vorlesung
Klaus Lagally, 22. Februar 2000, 19:36